statsExpressions: R Package for Tidy Dataframes and Expressions with Statistical Details
Source:vignettes/statsExpressions.Rmd
statsExpressions.RmdThis vignette can be cited as:
To cite package 'statsExpressions' in publications use:
Patil, I., (2021). statsExpressions: R Package for Tidy Dataframes
and Expressions with Statistical Details. Journal of Open Source
Software, 6(61), 3236, https://doi.org/10.21105/joss.03236
A BibTeX entry for LaTeX users is
@Article{,
doi = {10.21105/joss.03236},
year = {2021},
publisher = {{The Open Journal}},
volume = {6},
number = {61},
pages = {3236},
author = {Indrajeet Patil},
title = {{statsExpressions: {R} Package for Tidy Dataframes and Expressions with Statistical Details}},
journal = {{Journal of Open Source Software}},
}Summary
The statsExpressions package has two key aims: to provide a consistent syntax to do statistical analysis with tidy data, and to provide statistical expressions (i.e., pre-formatted in-text statistical results) for plotting functions. Currently, it supports common types of statistical approaches and tests: parametric, nonparametric, robust, and Bayesian t-test, one-way ANOVA, correlation analyses, contingency table analyses, and meta-analyses. The functions are pipe-friendly and compatible with tidy data.
Statement of Need
Statistical packages exhibit substantial diversity in terms of their syntax and expected input and output data type. For example, some functions expect vectors as inputs, while others expect data frames. Depending on whether it is a repeated measures design or not, functions from the same package might expect data to be in wide or tidy format. Some functions can internally omit missing values, while others do not. Furthermore, the statistical test objects returned by the test functions might not have all required information (e.g., degrees of freedom, significance, Bayes factor, etc.) accessible in a consistent data type. Depending on the specific test object and statistic in question, details may be returned as a list, a matrix, an array, or a data frame. This diversity can make it difficult to easily access all needed information for hypothesis testing and estimation, and to switch from one statistical approach to another.
This is where statsExpressions comes in: It can be thought of as a unified portal through which most of the functionality in these underlying packages can be accessed, with a simpler interface and with tidy data format.
Comparison to Other Packages
Unlike broom (Robinson, Hayes, & Couch, 2021) or parameters (Lüdecke, Ben-Shachar, Patil, & Makowski, 2020), the goal of statsExpressions is not to convert model objects into tidy data frames, but to provide a consistent and easy syntax to carry out statistical tests. Additionally, none of these packages return statistical expressions.
Consistent Syntax for Statistical Analysis
The package offers functions that allow users choose a statistical approach without changing the syntax (i.e., by only specifying a single argument). The functions always require a data frame in tidy format (Wickham et al., 2019), and work with missing data. Moreover, they always return a data frame that can be further utilized downstream in the workflow (such as visualization).
| Function | Parametric | Non-parametric | Robust | Bayesian |
|---|---|---|---|---|
one_sample_test |
✅ | ✅ | ✅ | ✅ |
two_sample_test |
✅ | ✅ | ✅ | ✅ |
oneway_anova |
✅ | ✅ | ✅ | ✅ |
corr_test |
✅ | ✅ | ✅ | ✅ |
contingency_table |
✅ | ✅ | - | ✅ |
meta_analysis |
✅ | - | ✅ | ✅ |
statsExpressions internally relies on
{stats} package for parametric and non-parametric (R Core Team, 2021),
WRS2 package for robust (Mair & Wilcox, 2020), and
BayesFactor package for Bayesian statistics (Morey & Rouder,
2020). The random-effects meta-analysis is carried out using
metafor (parametric) (Viechtbauer, 2010),
{metaplus} (robust) (Beath, 2016), and
metaBMA (Bayesian) (Heck et al., 2019) packages.
Additionally, it relies on easystats packages (Ben-Shachar, Lüdecke,
& Makowski, 2020; Lüdecke et al., 2020; Lüdecke, Ben-Shachar, Patil,
Waggoner, & Makowski, 2021; Lüdecke, Waggoner, & Makowski,
2019; Makowski, Ben-Shachar, &
Lüdecke, 2019; Makowski, Ben-Shachar,
Patil, & Lüdecke, 2020) to compute appropriate effect
size/posterior estimates and their confidence/credible intervals.
Tidy Dataframes from Statistical Analysis
To illustrate the simplicity of this syntax, let’s say we want to run a one-way ANOVA. If we first run a non-parametric ANOVA and then decide to run a robust ANOVA instead, the syntax remains the same and the statistical approach can be modified by changing a single argument:
oneway_anova(mtcars, cyl, wt, type = "nonparametric")
#> # A tibble: 1 × 15
#> parameter1 parameter2 statistic df.error p.value
#> <chr> <chr> <dbl> <int> <dbl>
#> 1 wt cyl 22.8 2 0.0000112
#> method effectsize estimate conf.level conf.low
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Kruskal-Wallis rank sum test Epsilon2 (rank) 0.736 0.95 0.624
#> conf.high conf.method conf.iterations n.obs expression
#> <dbl> <chr> <int> <int> <list>
#> 1 1 percentile bootstrap 100 32 <language>
oneway_anova(mtcars, cyl, wt, type = "robust")
#> # A tibble: 1 × 12
#> statistic df df.error p.value
#> <dbl> <dbl> <dbl> <dbl>
#> 1 12.7 2 12.2 0.00102
#> method
#> <chr>
#> 1 A heteroscedastic one-way ANOVA for trimmed means
#> effectsize estimate conf.level conf.low conf.high
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Explanatory measure of effect size 1.05 0.95 0.843 1.50
#> n.obs expression
#> <int> <list>
#> 1 32 <language>These functions are also compatible with other popular data manipulation packages. For example, we can use combination of dplyr and statsExpressions to repeat the same statistical analysis across grouping variables.
# running one-sample proportion test for `vs` at all levels of `am`
mtcars %>%
group_by(am) %>%
group_modify(~ contingency_table(.x, vs), .keep = TRUE) %>%
ungroup()
#> # A tibble: 2 × 14
#> am statistic df p.value method effectsize estimate conf.level conf.low
#> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 0 1.32 1 0.251 Chi-squ… Pearson's… 0.254 0.95 0
#> 2 1 0.0769 1 0.782 Chi-squ… Pearson's… 0.0767 0.95 0
#> # ℹ 5 more variables: conf.high <dbl>, conf.method <chr>,
#> # conf.distribution <chr>, n.obs <int>, expression <list>Expressions for Plots
In addition to other details contained in the data frame, there is
also a column titled expression, which contains a
pre-formatted text with statistical details. These expressions (Figure
1) attempt to follow the gold standard in statistical reporting for both
Bayesian (Doorn et al., 2020) and Frequentist
(American
Psychological Association and others, 2019) frameworks.
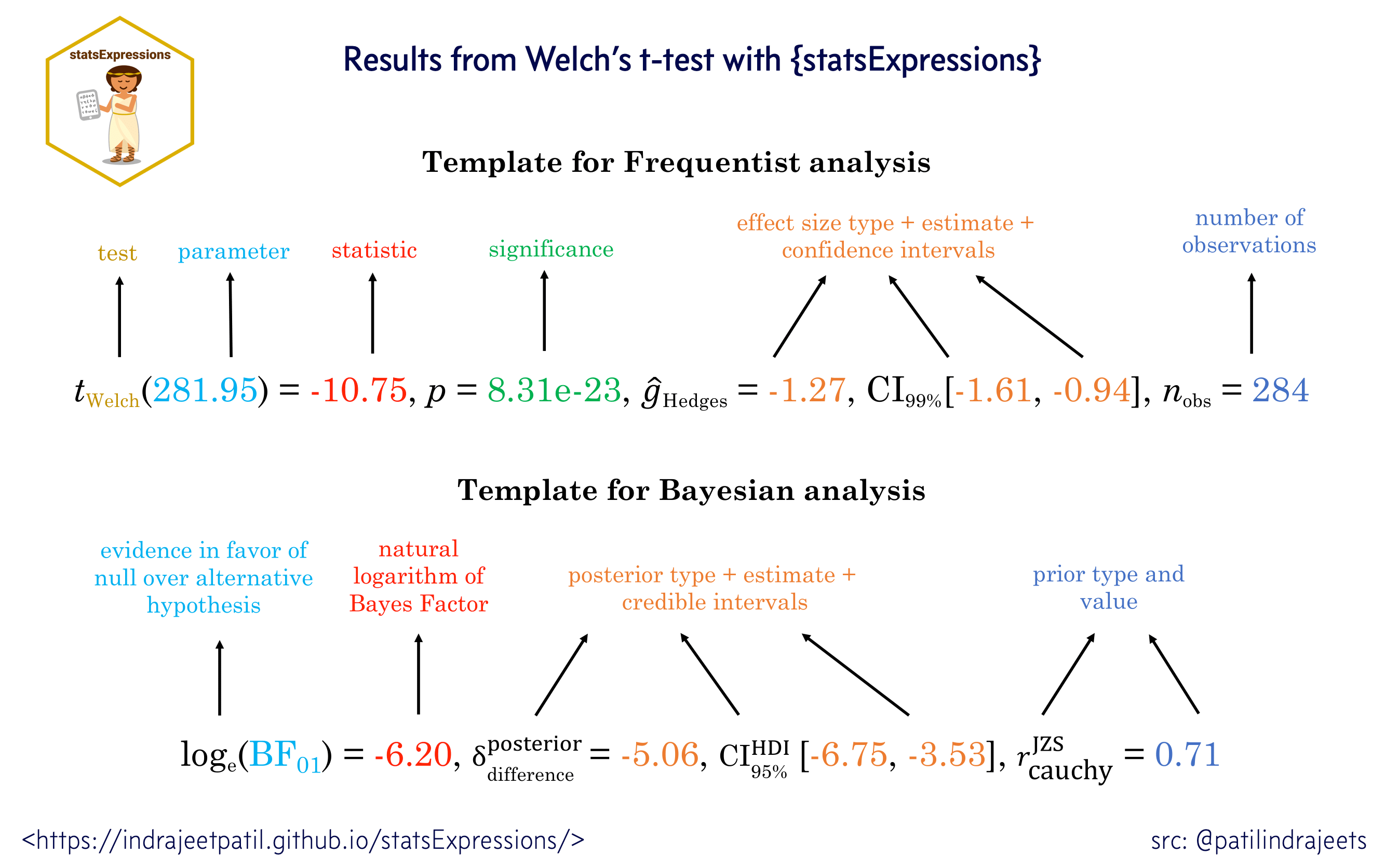
The templates used in statsExpressions to display statistical details in a plot.
This expression be easily displayed in a plot (Figure 2). Displaying statistical results in the context of a visualization is indeed a philosophy adopted by the ggstatsplot package (Patil, 2021), and statsExpressions functions as its statistical processing backend.
# needed libraries
library(ggplot2)
# creating a data frame
res <- oneway_anova(iris, Species, Sepal.Length, type = "nonparametric")
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_boxplot() + # use 'expression' column to display results in the subtitle
labs(
x = "Penguin Species",
y = "Body mass (in grams)",
title = "Kruskal-Wallis Rank Sum Test",
subtitle = res$expression[[1]]
)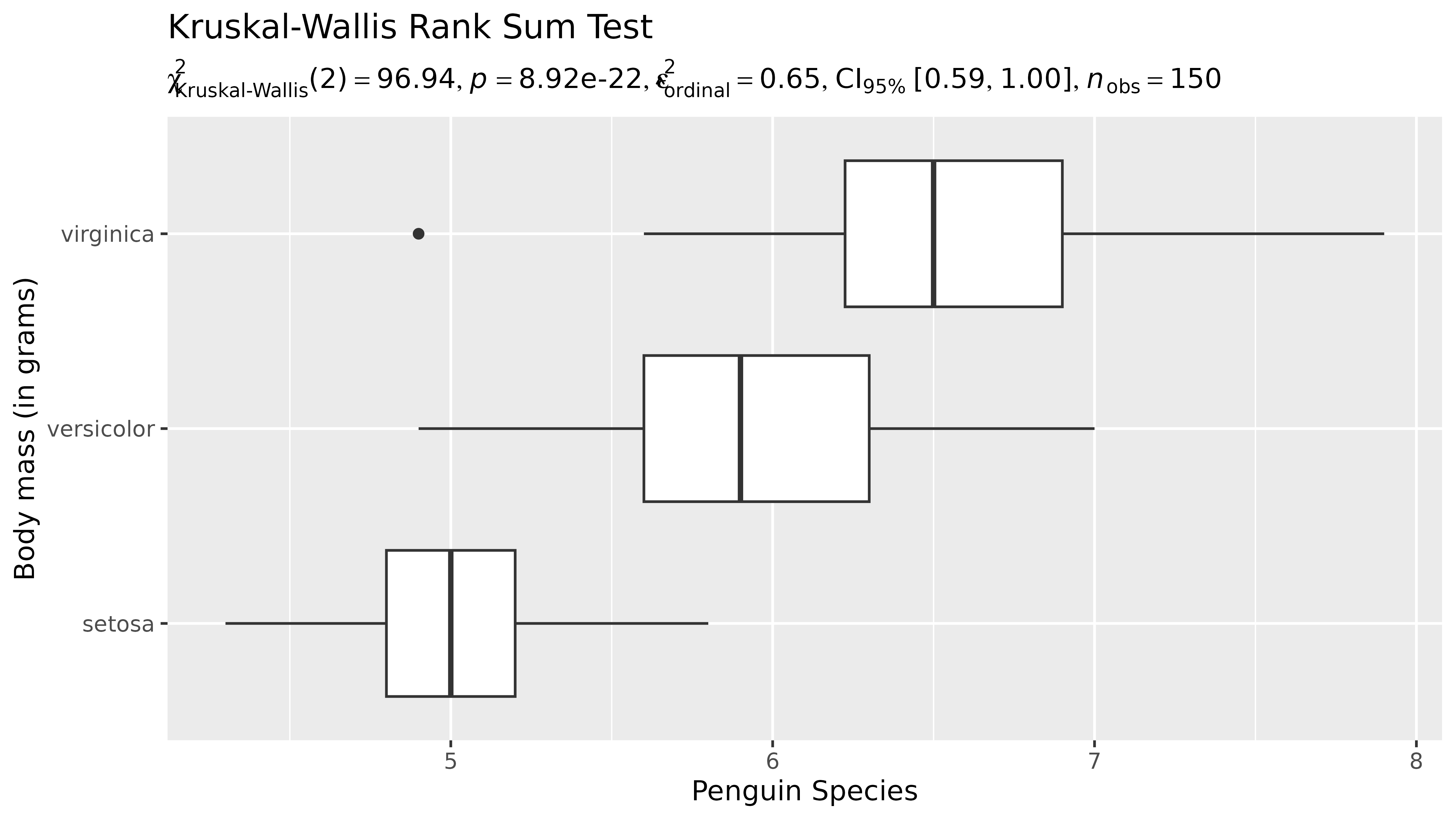
Example illustrating how statsExpressions functions can be used to display results from a statistical test in a plot.
Licensing and Availability
statsExpressions is licensed under the GNU General Public License (v3.0), with all source code stored at GitHub. In the spirit of honest and open science, requests and suggestions for fixes, feature updates, as well as general questions and concerns are encouraged via direct interaction with contributors and developers by filing an issue.
Acknowledgements
I would like to acknowledge the support of Mina Cikara, Fiery
Cushman, and Iyad Rahwan during the development of this project.
statsExpressions relies heavily on the easystats
ecosystem, a collaborative project created to facilitate the usage of
R for statistical analyses. Thus, I would like to thank the
members of
easystats as well as the users.